THE AUDITORY MODELING TOOLBOX
This documentation page applies to an outdated major AMT version. We show it for archival purposes only.
Click here for the documentation menu and here to download the latest AMT (1.6.0).
DEMO_MAY2011 - Demo of the model estimating the azimuths of concurrent speakers
Description
demo_may2011 generates figures showing the result of the model estimating the azimuth position of three concurrent speakers. Also, it returns the estimated azimuths.
Set demo to the following flags to shows other conditions:
- 1R
- one speaker in reverberant room
- 2
- two speakers in free field
- 3
- three speakers in free field (default)
- 5
- five speakers in free field
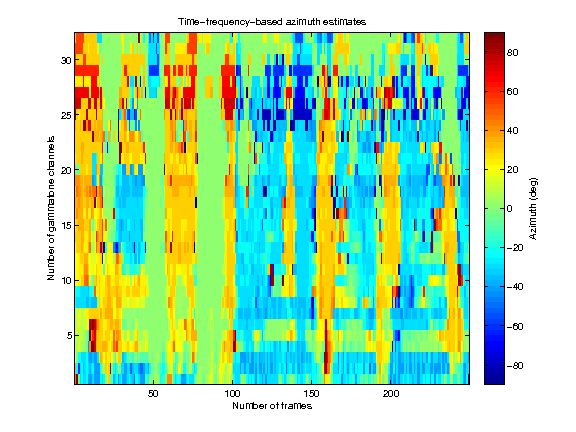
Time-frequency-based azimuth estimates
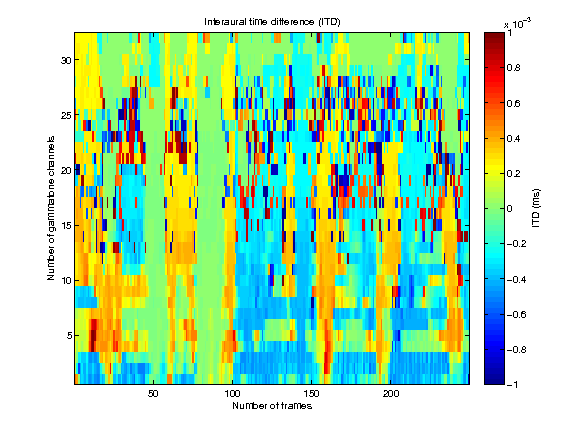
Interaural time differences (ITDs)
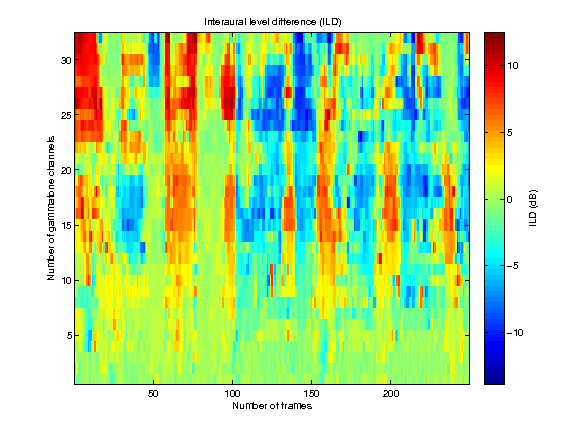
Interaural level differences (ILDs)
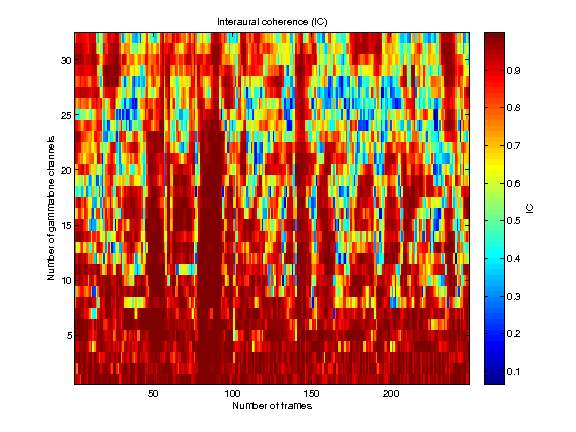
Interaural coherence
Frame-based azimuth estimates
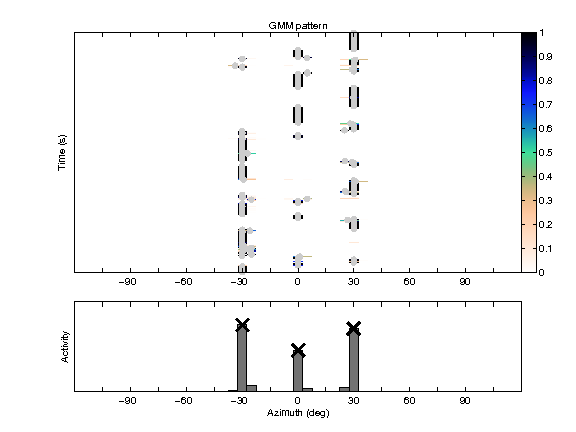
GMM pattern
This code produces the following output:
azEst = -29.8977 29.9242 0.0926
References:
T. May, S. van de Par, and A. Kohlrausch. A probabilistic model for robust localization based on a binaural auditory front-end. IEEE Trans Audio Speech Lang Proc, 19:1-13, 2011.















Build with Bootstrap